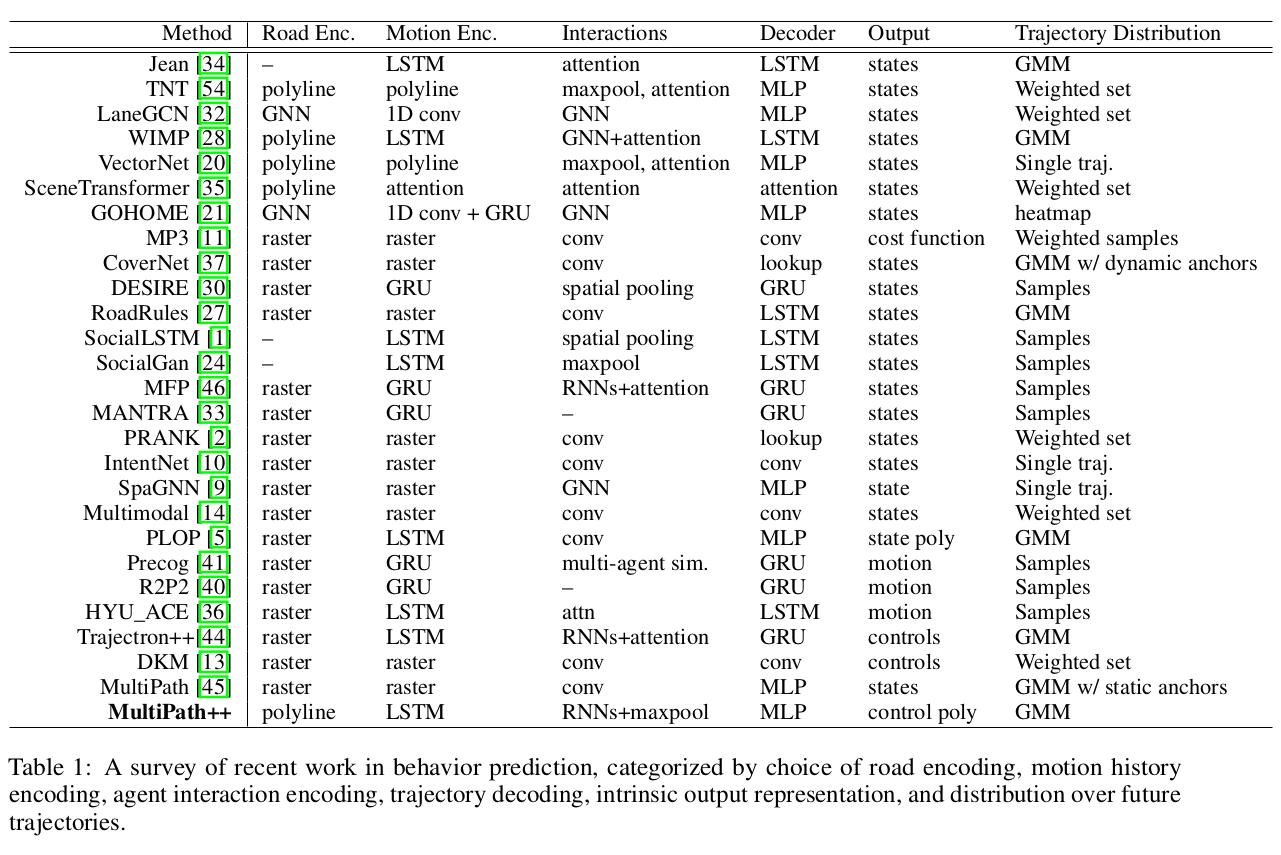
Multipath++: Efficient information fusion and trajectory aggregation for behacior prediction
Abstract
在实际的自动驾驶中,预测多模态的可能轨迹是重要的问题。waymo提出的本文模型采用multipath结构,并重访问选择的轨迹。模型特点如下:
- 道路特征使用稀疏的polylines表示;
- 自车状态直接使用原始状态信息(position, velocity, acceleration)
- 使用可重用的multi-context gating做信息融合;
- 使用pre-defined, static anchors,使用end2end方式学习latent anchor embeddings
- 探索了一种ensembling and output aggregation techniques,得到概率化的多模态输出表征
- achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition [12] and the Waymo Open Dataset Motion Prediction Challenge [18]
1 Introduction
- 当前面临的挑战:
- multimodal output space
- 固然的随机性
- 交互和预测错误导致高度多模态特性
- 模型需要符合潜在的模态分布
- Heterogenous, interrelated input space
- 环境表征包含高度异构的静态和动态输入
- 路网信息(车道几何、连通性、停止线、人行道)
- 交通灯信号、历史轨迹
- 环境表征包含高度异构的静态和动态输入
- multimodal output space
- multipath framework: Benjamin Sapp, Yuning Chai, Mayank Bansal, and Dragomir Anguelov. MultiPATH: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. In Conf. on Robot Learning, 2019.
- multipath框架建模多模态轨迹输出使用混合高斯模型(Gaussian Mixture Model),以及静态的轨迹anchor作为额外模型输入。
- weighted set是GMM的特例,其中只有均值和混合权重被建模
- rasterizing input的缺点:
- 空间网格分辨率、视野和计算要求之间难以权衡
- rasterizing本质是手工的特征工程,一些特征可能天然地难以表示再这样的框架中(e.g. radial velocity)
- 很难通过具有小感受野的卷积来捕捉长程的交互过程;
- 内容信息稀疏,计算资源浪费;
- In this paper, we introduce MultiPath++, which builds upon
MultiPath, taking its output GMM representation and concept of anchors,
but reconsidering how to represent and combine highly heterogeneous
world state inputs and model interactions between state elements.
MultiPath++ introduces a number of key upgrades:
- 避免使用rasterizing input和CNN,而使用更紧凑的状态描述(compact state description),将道路信息元素表示为polylines,将历史信息用RNN编码,有利于长程依赖的建模。因此计算复杂度只随场景中元素的数量而变化,和空间网格分辨率无关;
- 独立编码每个元素不如建模他们之间的交互关系(例如道路编码和相应的agent绑定)。因此,提出了multi-context gating (MCG),它将输入元素条件编码(encoding are conditioned)为内容总结向量(summary context vector);
- 进一步设计了一种学习潜在anchor的方法,并显示它们优于multipath的原始静态anchor,同时将模型创建简化为单步过程;
- 模型结合了ensembling techniques, 考虑miss-rate (MR),miss-rate (MR),mean Average Precision (mAP)等指标,输出one of greedy iterative clustering,使用EM算法最大化概率化目标;
2 Related Work
- road encoding:
- raster
approach:编码世界为多通道的鸟瞰图(BEV),包括道路信息、历史轨迹、信息空间关系。之后再用现成的高性能的CNN网络进行处理。
- 缺点:难以建模大范围的交互,受限的视野,难以表征连续的物理状态;
- ployline approach:将车道线、人行道、路沿表示为分段的线段,相较于路网的稀疏性,该表示方式是更为紧凑的。
- raster
approach:编码世界为多通道的鸟瞰图(BEV),包括道路信息、历史轨迹、信息空间关系。之后再用现成的高性能的CNN网络进行处理。
- motion history:
- 主流的方式是使用RNN(GRU, LSTM)或者是1D temporal convolution encode历史状态序列,
- 在raster框架下,状态序列被渲染为描绘agent矩形框的一堆二值化的mask image,也有一些工作将历史信息和当前信息分离,但渲染在一个图层上
- agent interactions:
- 通常做法是只处理离自车最近的k个障碍物,使用pooling or soft attention。raster方法依赖2D卷积来隐含地捕获交互过程,长程交互取决于网络的感受野。
- trajectory decoding:
- 和motion history编码的选择类似,此外还可以在固定的或学习的轨迹簇上进行查找;
- popular output trajectory representation:
- 状态序列或者状态差
- 本质上表示为样本点序列或连续多项式表示
- HOME [22] and GOHOME [21]首先预测heatmap,然后在采样之后encode轨迹
- [21] Thomas Gilles, Stefano Sabatini, Dzmitry Tsishkou, Bogdan Stanciulescu, and Fabien Moutarde. Gohome: Graph-oriented heatmap output for future motion estimation. arXiv preprint arXiv:2109.01827, 2021.
- [22] Thomas Gilles, Stefano Sabatini, Dzmitry Tsishkou, Bogdan Stanciulescu, and Fabien Moutarde. HOME: heatmap output for future motion estimation. CoRR, abs/2105.10968, 2021.
- MP3 [11] 和 NMP [52]
学习轨迹的损失函数评估模型,然后启发式地枚举而不是通过学习模型生成
- [11] Sergio Casas, Abbas Sadat, and Raquel Urtasun. Mp3: A unified model to map, perceive, predict and plan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14403–14412, 2021.
- [52] Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. In CVPR, 2019.
- trajectory distribution:
- 需要描述多模态的轨迹,流行的选择是使用GMMs
- 一些方法使用training tricks [14, 50] or trajectory anchors [45]
- 其它的模型建模离散分布的轨迹集合(learned or fixed a priori),或者通过从潜在分布中采样轨迹,并通过模型解码
3 Model Architecture
- multipath++的架构和multipath相似,包含一个编码步骤和一个预测器head,它依赖anchors、输出agent未来时间步位置的GMM分布
- 模型框架图:
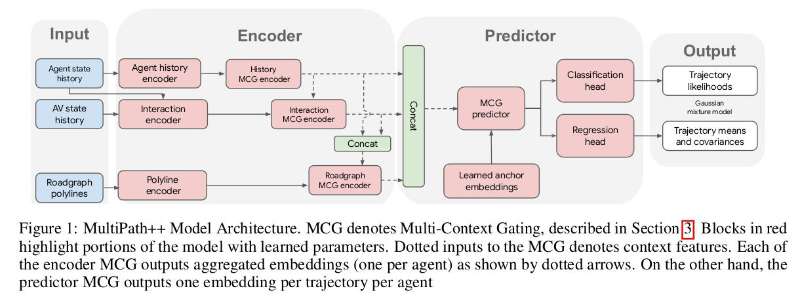
3.1 Input Representation
模型输入:
Agent state history
waymo open motion dataset 上,信息包括位置、速度、3D bounding box、heading和object type;Argoverse中只有位置信息;这些信息需要转换为agent为中心的坐标系,车头向东;
Road network
使用clothoids 之类的参数化曲线表达lane lines, cross walks, and stop lines,以方便采样为点集;这里本文进一步使用折线来表达;
Agent interactions
会考虑智能体周围所有临近的障碍物,对于每个临近的障碍物,考虑其relative orientation, distance, history and speed
AV-relative features
将自动驾驶车辆(autonomous vehicle,AV)和感知的到车辆区别建模,因为(1)AV始终位于感知范围中心位置;(2)假设AV的驾驶行为和其它road user不相似;
这些特征的encode方式见上图encoder部分。
3.2 Multi Context Gating for fusing modalities
common rasterized format:
- Benjamin Sapp, Yuning Chai, Mayank Bansal, and Dragomir Anguelov. MultiPATH: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. In Conf. on Robot Learning, 2019.
- Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. In CVPR, 2019.
a simple concatenation of encodings:
- Namhoon Lee, Wongun Choi, Paul Vernaza, Christopher B Choy, Philip H S Torr, and Manmohan Chandraker. DESIRE: Distant future prediction in dynamic scenes with interacting agents. In CVPR, 2017.
- Nicholas Rhinehart, Rowan McAllister, Kris Kitani, and Sergey Levine. PRECOG: Prediction conditioned on goals in visual multi-agent settings. In Intl. Conf. on Computer Vision, 2019.
attention:
- Jiyang Gao, Chen Sun, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid. VectorNet: Encoding hd maps and agent dynamics from vectorized representation. In CVPR, 2020.
- Ming Liang, Bin Yang, Rui Hu, Yun Chen, Renjie Liao, Song Feng, and Raquel Urtasun. Learning lane graph representations for motion forecasting. arXiv preprint arXiv:2007.13732, 2020.
- Jiquan Ngiam, Benjamin Caine, Vijay Vasudevan, Zhengdong Zhang, Hao-Tien Lewis Chiang, Jeffrey Ling, Rebecca Roelofs, Alex Bewley, Chenxi Liu, Ashish Venugopal, David Weiss, Benjamin Sapp, Zhifeng Chen, and Jonathon Shlens. Scene transformer: A unified multi-task model for behavior prediction and planning. CoRR, abs/2106.08417, 2021.
multi-context gating (MCG) (this paper)
给定一个集合
和一个内容向量 ,MCG模块输出 和输出内容向量 ,输出不取决于输入元素的顺序。 表示对这 个元素序列的某种排序操作,整个过程数学表达为: 这意味着顺序的不变性 (permutation-invariance),以及顺序的等价性 (permutation-invariance) 这些性质适合用来编码路网信息和车辆间的关系,一些集合函数
DeepSets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
PointNet
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017.
SetTransformers
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 3744–3753. PMLR, 2019.
一个单个CG block 的实现方式:
其中 表示element-wise product, 是一个满足顺序不变性的池化层(max or average pooling)。CG block的结构见下图: 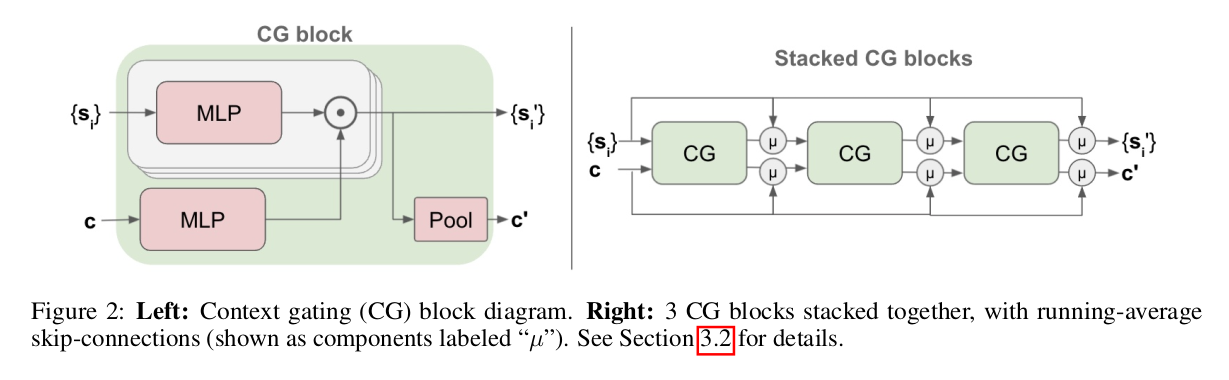
堆栈多个CG block时,参考残差网络的形式:
将多层CG块表示为 ,即N个CG blocks 与attention比较:
- self-attention聚合道路信息复杂度
- cross-attention聚合n个智能体和m个道路元素复杂度
- CG可被视为cross-attention的一个近似,示意图如下Figure 3,A
comparison of the element relationship graph for cross-attention and CG.
In cross-attention, each element
aggregates information from . In CG, summarized with a single context vector . 因此c的维度需要足够大,能够容纳原始m个元素的编码信息,如果元素的维度是 ,那么 的维度应该为
- self-attention聚合道路信息复杂度

3.3 Encoders
Agent history encoding
- A LSTM on the history features from H time steps ago to the present
time:
- A LSTM on the difference in the history features
- MCG blocks applied to the set of history elements. 集合中每个元素包含历史位置和时间偏差(以秒为单位)。内容输入是一个all-one 向量以及一个带有身份信息MLP。此外还将历史帧id编码为一个one hot vector 以消除历史步骤的歧义。
上述三个信息被编码为
,这个过程称为final embedding - A LSTM on the history features from H time steps ago to the present
time:
Agent interaction encoding
实现交互编码通过考虑临近agent v 的历史状态观测值
,并且转换agent v的状态到自车的坐标系下,使用LSTM获得embedding 。这一步类似于 ego-agent 的历史embedding,只不过ego不适用其它agent的坐标系 对临近的 n 个agents进行编码后,可以获得交互embedding的集合
, 然后通过MCG blocks实现信息融合 其中,MCG的第二个参数是输入内容向量(input context vector),在这个case中是串联的agent历史embedding,以及自动驾驶车辆的交互embedding。通过这种形式区分ego和他车。
Road network encoding
使用折线表征,使用start point, end point, road element semantic type
实现参数化。 只处理最近的
条折线,转换到参考坐标系,并称为转换后的线段, 假设
是线段(segment)离agent最近的点, 是原始曲线上 点的单位切向量(unit tangent vector),通过向量 表征智能体和线段之间的空间关系 这些特征向量通过shared MLP进行处理,生成每个道路线段的依赖于智能体的embedding(agent-specific embeddings per road segment),记为
通过 stacked MCG blocks 融合 road element embeddings 和 agent history embedding
,从而实现动态状态信息的嵌入
3.4 Output representation
使用混合高斯分布(Gaussian Mixture Model, GMM)表示预测结果
为了高效地长程预测(long-term),分布在每个时间步都是条件独立的,坐标
满足均值 ,方差 ,这 个模块的可能性 与时间相关,每个模态的状态推理也是均等的 步时间序列,最终后成为waypoint,表示未来智能体的轨迹 完整的输出分布为:
其中, 表示一条轨迹, 每个类别的head 预测
并使用softmax进行轨迹选择。regression head 输出 个模态 个时间步的高斯分布的参数 和 Training objective.
- 与MultiPath算法的目标保持一致,最大化预测输出和真值的似然度
- 使用硬分配标签(hard-assignment labeling),选择与真值具有最小欧式距离误差的输出模态为“正确”的输出,
- 整个训练过程中的log loss使用adam优化,初始学习率0.0002;batch size 64;衰减率0.5每2个epochs(用所有样本训练2轮);最终模型训练800, 000 steps;
3.5 Prediction architecture with learned anchor embeddings
- 预测的结果是M条轨迹的GMM参数,即轨迹点的似然度与不确定性
- 沿用multipath++利用anchor trajectories作为预先定义的模态的方案
- 缺点:需要预先定义大量的模态,否则效果不好,获得很低的似然度或者被舍弃;另外,增加了额外步骤——增加了2阶段学习过程的复杂性和工作量(首先从数据中估计模态,然后训练网络)
- 本文将学习anchor embedding作为模型训练的一部分。解释这些embedding
作为潜在空间中的anchors,使得每个embedding和GMM输出轨迹有一对一的对应关系 - 和MANTRA类似,
是独立于输入的可训练的模型参数,避免了手工设计anchors - Francesco Marchetti, Federico Becattini, Lorenzo Seidenari, and Alberto Del Bimbo. Mantra: Memory augmented networks for multiple trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7143–7152, 2020.
- 从各个模块的MCG获得embedding
and ,将其拼接为 - 之后将堆栈的
和anchor embedding 输入给MCGs,再经过一个MLP来预测GMM所有的参数
其中
3.6 Internal Trajectory Representation
参数化轨迹为
, , , , (位置,heading,标准差,纵向和横向不确定性) 轨迹使用均匀时间离散化,本文考虑两个非互斥的变体
将函数随时间的变化表示为多项式,这增加了一个感应偏差,但确保了一个平滑的轨迹。提供了每个预测信号的一个紧凑的、可解释的表示。
没有直接预测
, 而是预测潜在的运动学控制信号,然后积分推导出需要的状态输出。在本文中,我们预测加速度和朝向角变化率,然后对其积分:
这样的轨迹表征增加了感知偏差,但更鼓励自然、真实的轨迹。基于现实的运动学和当前状态的约束。在多项式表征的步骤中,也会将其作为一个软约束考虑
4 Ensembling predictor heads via bootstrap aggregation
aggregation在图像分类中是常用的技术,用多个模型的投票作为最后的结果,使我们可以享受具有较低统计方差的较高容量模型的好处
使用 bootstrap aggregation (bagging)
训练
个预测头,鼓励模型学习互补的(complementary)信息,并且这 个头的权重用随机初始化。每个头的更新概率为 但是如何结合多个头的输出结果并不是一目了然的,GMM 缺乏每个头的混合部件,我们允许每个预测头去预测更多的
个模态( ), 个头的数量是先验固定的 定义
表示所有head的预测结果 其中, ,模态的似然度 对 个head求和后和为1 将
表达为更紧凑的 个模态的 使用iterative clustering algorithm,用
拟合 ,类似EM算法 首先用greedy算法选择
个簇,质心为 。选择的标准是,在距离误差 以内,最大化从 中采样的均值 模型指标:为了衡量多样性,度量miss rate使用mAP,minADE,以及spatial heatmap representation
- Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. In CVPR, 2019.
- Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles Qi, Yin Zhou, Zoey Yang, Aurelien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, and Dragomir Anguelov. Large scale interactive motion forecasting for autonomous driving : The waymo open motion dataset, 2021.
考虑联合优化
是困难的,只用贪婪方法选择 与之前不同之处在于外部的 是依据 迭代,而不是 根据选择好的质心(均值),使用 Expectation-Maximization 迭代更新
的参数,更新方式为: 其中 是给定样本 后,从 对应的GMM的采用第 个组件的先验概率。计算方式如下: