Mastering Atari, Go, chess and shogi by planning with a learned model
MuZero是AlphaGo Zero之上的第二次改进。第一次改进为AlphaZero,一个模型实现围棋、国际象棋、将棋的超人水平。此次在AlphaZero基础上,更是从棋类拓展到了更具有普遍意义的Atari游戏。
训练模型的规划能力通常是较为困难的,本文提出MuZero,一个结合学习模型的树搜索方法
1 Introduction
- model-based RL 需要
- 状态转移模型:根据是s,a预测下一时刻的状态
- 奖励模型:预测期望的奖励
2 MuZero algorithm
构建一个模型
预测三个未来的量: - Policy
- Value function
- immediate reward
表示真实的观测到的奖励, 表示用于选择真实行为的策略 - Policy
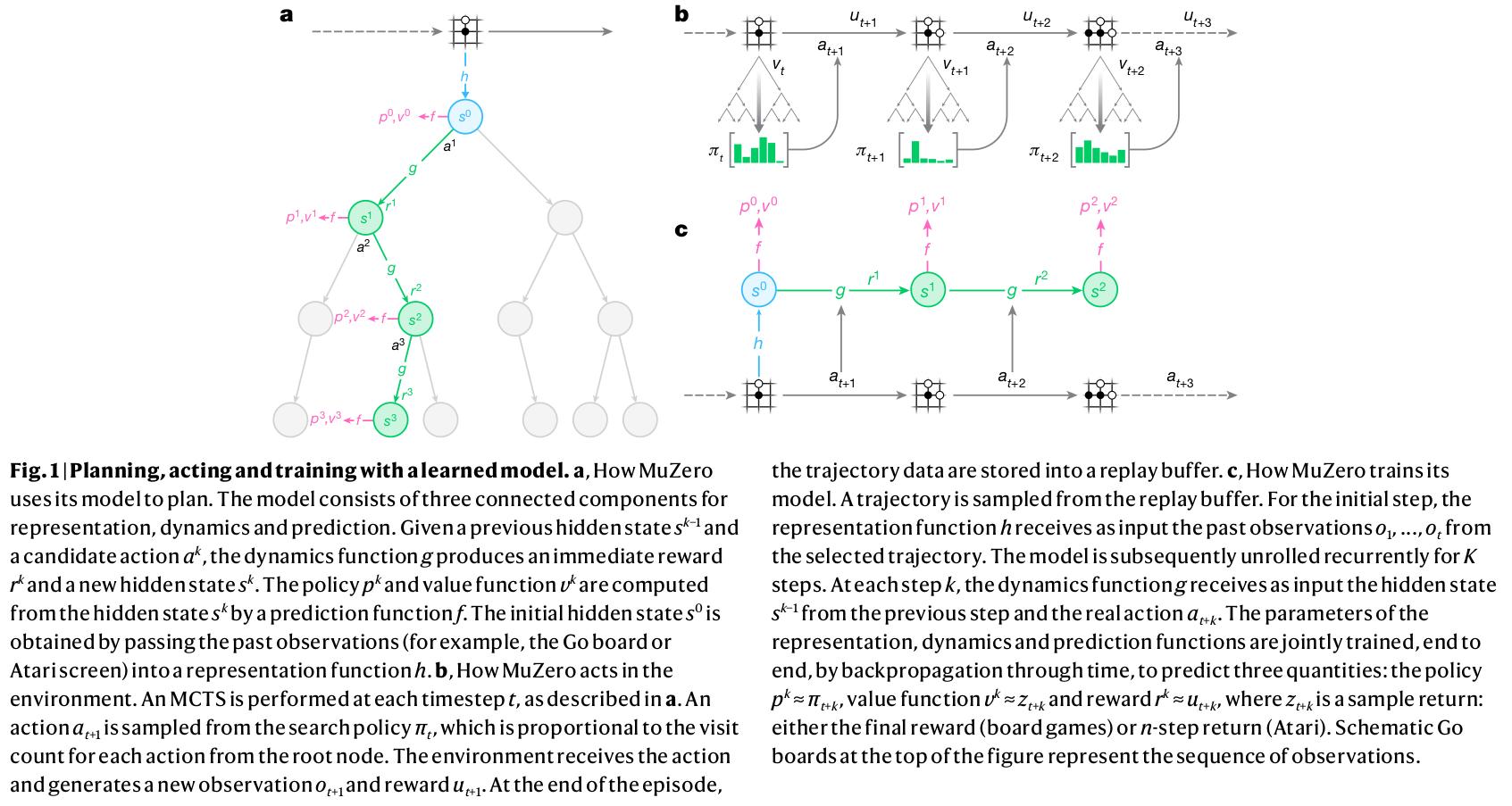
具体地,模型包括三个部分:
- dynamics function:
,在每个假设步骤k执行, 是即时奖励; 是内部状态表征(internal state),其没有环境信息的语义含义,只是用于准确预测未来变量policies, values and rewards - prediction function:
- representation function:
,根据过去的观测信息生成根节点的内部状态表征
- dynamics function:
利用上述模型,可以利用过去的观测信息
,生成假设的未来轨迹 损失函数:(每一项都是L2损失函数)
policy损失, value损失 and 即时reward损失
总结