Mastering the game of Go without human knowledge
AlphaGo和AlphaGo Master之后的又一力作,不同于AlphaGo学习人类棋谱,利用人类先验知识,AlphaGo Zero完全自学,并在学习三天后超越了AlphaGo,40天超越了AlphaGo Master。
1 Introduction
Reinforcement learning in AlphaGo Zero
算法的特点是将RL的策略网络和价值网络合并,只改变输入层。神经网络表示为
- 输入:棋局表征
及其历史信息 - 输出:下一步的落子概率
,当前局面获胜概率 - 训练目标是去拟合自我对弈里面产生的真实胜率
和下面提到的 MCTS 产生的落子概率 ,即 。
- 输入:棋局表征
MCTS(蒙特卡洛树搜索)使用
进行自博弈,搜索策略 一般优于网络估计的 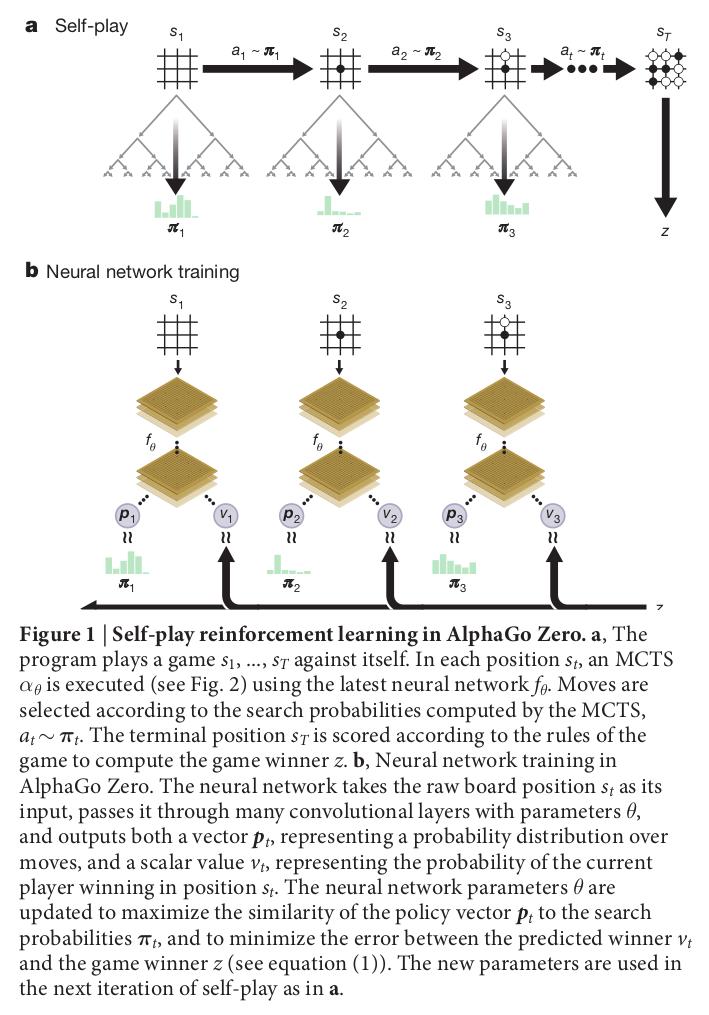
因此,基于以下两点,可以实现训练:
- MCTS 优于网络
; 性能提升后,MCTS自博弈的结果也更好,两者相互促进提升;
- MCTS 优于网络
MCTS:
搜索树使用神经网络策略引导仿真(自博弈)
搜索树的每一条边有一个先验概率
,一个访问数(visit count) ,一个行为价值 每次仿真从根节点开始迭代进行,最大化置信上界
,直到达到访问过的叶子节点。 每个叶子节点位置仅被网络扩展和评估一次,以生成先验概率和评估值;
每条边
每使用一次就增加访问数 ,并更新行为价值为仿真中的平均估计值, MCTS 使用的节点选择策略正比与节点访问数
, 是温度系数; 仿真直到搜索的价值低于阈值或者到达最大次数,此时给出最终奖励
每一时间步的数据存为
, 是当前玩家在第 步成为赢家获得的奖励 网络优化:
损失函数为均方误差+交叉熵损失+网络权重的平方:
Empirical analysis of AlphaGo Zero training
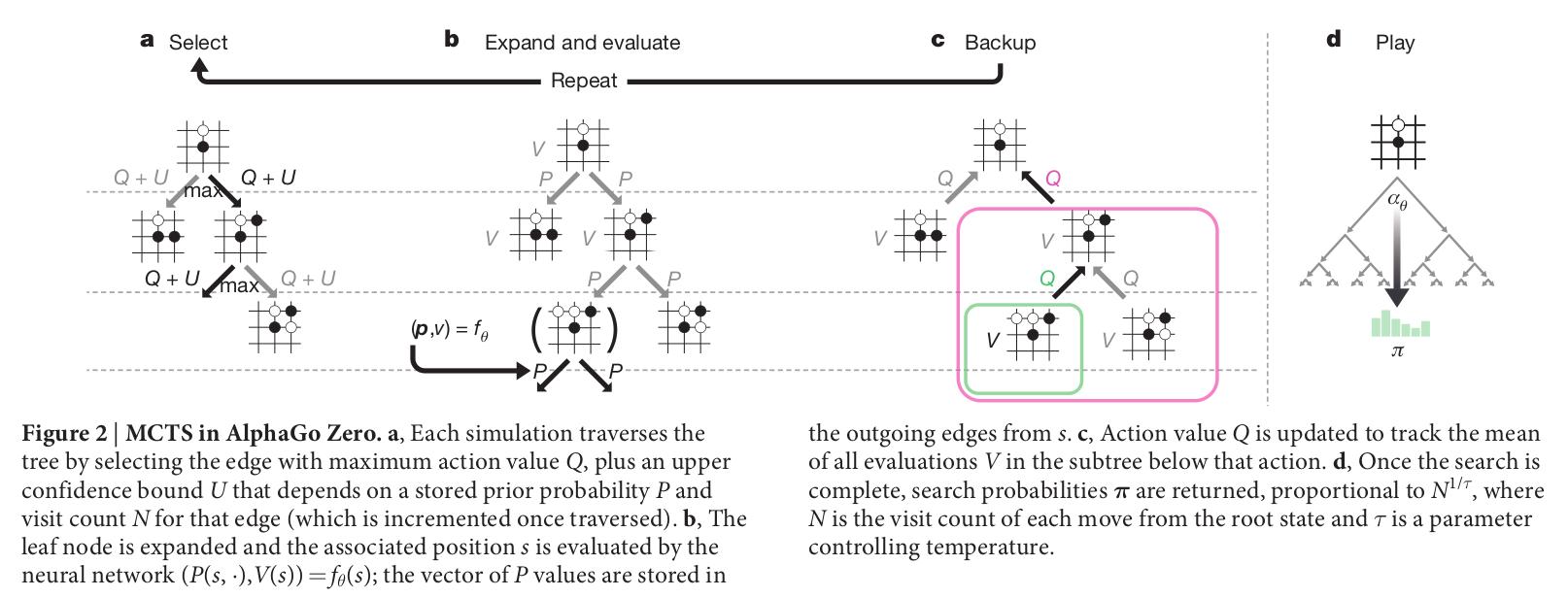
MCTS行为选择策略为:
a.选择 每次仿真通过选择动作值Q和置信上限U之和最大的边来遍历树,U取决于存储的先验概率P和该边的访问次数N(一旦遍历就递增)。
b.扩展 扩展叶子节点,并用神经网络评估相应的棋局状态s
c.更新 行为价值Q被更新以跟踪该动作下的子树中所有评估值V的平均值
d.仿真 搜索完成后,将返回概率
,其与 成比例,N是从根状态开始的节点访问计数, 是温度参数。 附录有详细的MCTS计算方法!
后续性能展示过于知名,不再赘述
总结
MCTS与神经网络结合的思路可以借鉴,目前不清楚在其它任务中该框架的训练难度(GPU需求量)